Data Ingestion Architecture for Financial AI Agent Platforms

Executive Summary
The effectiveness of a financial AI agent platform fundamentally depends on its ability to ingest, process, and make accessible diverse data types from multiple sources. This article presents a comprehensive data ingestion architecture designed to support multi-layered AI agent systems, with particular focus on handling both structured financial transactions and unstructured business knowledge.
1. Data Classification and Strategic Approach
1.1 Structured Transactional Data
Characteristics:
- Financial transactions following double-entry bookkeeping principles
- General ledger entries with debit-credit pairs
- Chart of accounts mappings
- Historical transaction data with temporal attributes
- Quantitative metrics and financial KPIs
Strategic Approach: Store in relational databases (PostgreSQL, SQL Server) with optimized schemas for:
- Fast aggregation queries for P&L composition
- Temporal queries for historical analysis
- Complex joins across multiple financial dimensions
- ACID compliance for data integrity
Processing Agent: SQL-based Financial Data Agent with capabilities for:
- Complex analytical queries
- Real-time transaction processing
- Financial calculations and aggregations
- Data validation and reconciliation
1.2 Semi-Structured Business Data
Characteristics:
- Customer relationship data with varying attributes
- Product catalogs with hierarchical categories
- Inventory records with location and status information
- Employee profiles with organizational hierarchies
- Sales pipeline data with stages and activities
Enhanced Approach (Hybrid Strategy): Rather than treating this as purely unstructured data, implement a dual-storage strategy:
- Core Entities in Relational Database:
- Extended Attributes in Document Store:
Processing Agents:
- Relational Query Agent: For structured queries, aggregations, and joins
- Hybrid Search Agent: Combines SQL queries with vector similarity search
- Context Enrichment Agent: Augments structured results with document-based context
1.3 Unstructured Knowledge Base
Characteristics:
- Policy documents and procedure manuals
- Contracts and legal agreements
- Email communications and meeting notes
- Market research and competitor analysis
- Industry reports and regulatory documentation
- Internal wiki and knowledge articles
Strategic Approach: Vector database with:
- Semantic embeddings for similarity search
- Metadata tagging for filtering and classification
- Document chunking strategies for optimal retrieval
- Version control for document updates
Processing Agent: RAG-enabled Knowledge Agent with:
- Semantic search capabilities
- Context-aware retrieval
- Multi-document synthesis
- Source attribution and confidence scoring
2. Comprehensive Data Ingestion Architecture
2.1 Ingestion Layer Components
Real-Time Transaction Ingestion Pipeline
Purpose: Capture financial transactions as they occur across various business systems
Components:
- Event Stream Processors: Apache Kafka or AWS Kinesis for handling high-volume transaction streams
- Transaction Parsers: Custom parsers for different source formats (API responses, file uploads, EDI messages)
- Transformation Engine: Convert diverse transaction formats into standardized debit-credit records
- Validation Layer: Business rule validation, duplicate detection, anomaly flagging
- Loading Service: Optimized batch and streaming loaders for database insertion

Batch Data Ingestion Pipeline
Purpose: Handle periodic imports from external systems and file-based sources
Components:
- File Processors: Support for CSV, Excel, JSON, XML, EDI, and custom formats
- FTP/SFTP Monitors: Automated file detection and retrieval
- API Connectors: RESTful and GraphQL integrations with external systems
- Staging Area: Temporary storage for data quality checks before loading
- Reconciliation Engine: Compare imported data with expected values and patterns
Supported Sources:
- ERP systems (SAP, Oracle, NetSuite, Microsoft Dynamics)
- Banking platforms and payment processors
- Accounting software (QuickBooks, Xero, Sage)
- CRM systems (Salesforce, HubSpot)
- HR systems (Workday, BambooHR)
- E-commerce platforms (Shopify, WooCommerce, Magento)
- Supply chain systems (SAP SCM, Oracle SCM Cloud)
Document and Knowledge Ingestion Pipeline
Purpose: Process unstructured content into searchable, retrievable knowledge
Components:
- Document Parsers: Extract text from PDFs, Word docs, emails, presentations
- OCR Engine: Process scanned documents and images
- Content Extractors: Pull data from web pages, APIs, databases
- Chunking Strategy Engine: Intelligent document segmentation for optimal retrieval
- Embedding Generator: Create vector representations using models like OpenAI Ada or Sentence Transformers
- Metadata Extractor: Automatic classification, tagging, and entity recognition
- Vector Database Loader: Store embeddings with metadata in vector store
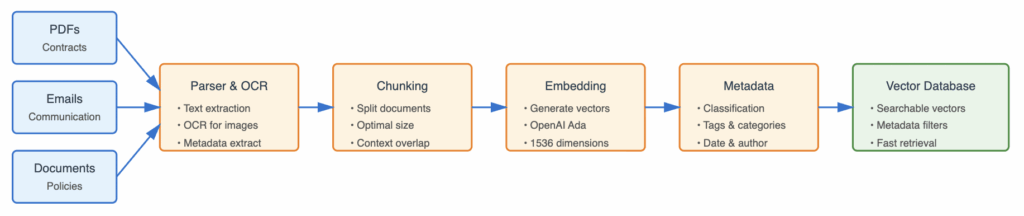
2.2 Data Transformation and Standardization
Transactional Data Transformation
Standardized Transaction Schema:
Transaction Record:
- transaction_id (unique identifier)
- transaction_date (timestamp)
- source_system (originating system)
- account_debit (chart of accounts code)
- account_credit (chart of accounts code)
- amount (monetary value)
- currency (ISO currency code)
- business_unit (organizational dimension)
- cost_center (cost allocation dimension)
- product_id (optional product reference)
- customer_id (optional customer reference)
- vendor_id (optional vendor reference)
- description (transaction narrative)
- reference_number (external reference)
- status (posted, pending, reversed)
- metadata (JSON for additional attributes)Transformation Rules:
- Account Mapping: Map source system accounts to standardized chart of accounts
- Currency Normalization: Convert all transactions to base currency with exchange rate tracking
- Dimension Enrichment: Add organizational dimensions (department, region, product line)
- Classification: Assign transaction types (revenue, expense, asset, liability)
- Period Assignment: Allocate to accounting periods based on recognition rules
Master Data Harmonization
Challenge: Customer, product, and vendor records exist in multiple systems with different identifiers and structures
Solution: Master Data Management (MDM) Layer
Components:
- Entity Resolution: Match and merge duplicate records across systems
- Golden Record Creation: Establish single source of truth for each entity
- Identity Mapping: Maintain cross-reference between system-specific IDs and master IDs
- Data Quality Rules: Standardize formats, validate completeness, enforce constraints
- Change Data Capture: Track modifications to master records over time
Example – Customer Master Record:
Master Customer Record:
- master_customer_id (universal identifier)
- system_ids (map of source_system → local_id)
- legal_name
- common_name
- tax_id
- addresses (array with types: billing, shipping, etc.)
- contact_methods (array: email, phone, etc.)
- classification (industry, size, risk_rating)
- relationship_data (account_manager, contract_terms)
- lifecycle_status (prospect, active, inactive)
- metadata (JSON for system-specific attributes)2.3 Data Quality and Validation Framework
Multi-Stage Validation Process
Stage 1: Format Validation
- Schema conformance (data types, required fields)
- Range checks (dates, amounts within expected bounds)
- Format validation (email addresses, phone numbers, tax IDs)
Stage 2: Business Rule Validation
- Debit-credit balance checks
- Account code existence validation
- Valid entity references (customer IDs, product SKUs)
- Authorization limits and approval requirements
Stage 3: Consistency Validation
- Cross-system reconciliation
- Duplicate detection
- Temporal consistency (transaction dates vs. posting dates)
- Referential integrity checks
Stage 4: Anomaly Detection
- Statistical outlier identification
- Pattern deviation detection (unusual amounts, frequencies)
- Fraud indicator flagging
- ML-based anomaly scoring
Error Handling Strategy:
- Blocking Errors: Prevent data loading until resolved (e.g., invalid account codes)
- Warning Errors: Load with flag for review (e.g., unusual amounts)
- Auto-Correction: Apply predefined fixes for known issues (e.g., format standardization)
- Quarantine Queue: Route problematic records to manual review workflow
2.4 Incremental and Change Data Capture
Challenge: Efficiently update data without full reloads while maintaining history
Strategies:
For Transactional Data:
- Append-Only Model: New transactions continuously added to transaction table
- Temporal Tables: Maintain effective dates for retroactive adjustments
- Audit Trail: Track all modifications with user, timestamp, and reason codes
- Soft Deletes: Mark records as inactive rather than physical deletion
For Master Data:
- Change Data Capture (CDC): Track changes at source systems
- Version History: Maintain complete history of all attribute changes
- Effective Dating: Track when changes become effective for reporting
- Slowly Changing Dimensions (SCD): Implement Type 2 SCD for historical accuracy
For Knowledge Base:
- Document Versioning: Track document revisions with timestamps
- Incremental Embedding: Only re-process modified documents
- Metadata Updates: Update classification without re-embedding
- Relevance Scoring: Decay scores for older documents based on configurable policies
3. Agent-Specific Data Access Patterns
3.1 Financial Transaction Agent (SQL-Based)
Responsibilities:
- Execute complex financial queries across transaction and master data
- Perform real-time P&L calculations
- Generate balance sheets and cash flow statements
- Conduct variance analysis and trend calculations
- Support drill-down queries from summary to detail
Optimized Data Access:
- Pre-aggregated Tables: Summary tables for common queries (daily/monthly rollups)
- Materialized Views: Pre-computed joins for frequent access patterns
- Indexed Dimensions: Optimize filtering by date, account, entity, product
- Partitioning Strategy: Partition large tables by date ranges for query performance
- Query Caching: Cache results for common queries with appropriate TTL
Example Query Patterns:
-- P&L by period and business unit
SELECT
period,
business_unit,
account_category,
SUM(CASE WHEN account_type = 'REVENUE' THEN amount ELSE 0 END) as revenue,
SUM(CASE WHEN account_type = 'EXPENSE' THEN amount ELSE 0 END) as expenses,
SUM(CASE WHEN account_type = 'REVENUE' THEN amount
WHEN account_type = 'EXPENSE' THEN -amount
ELSE 0 END) as net_income
FROM standardized_transactions
WHERE period BETWEEN '2025-01' AND '2025-12'
GROUP BY period, business_unit, account_category;3.2 Knowledge Retrieval Agent (RAG-Based)
Responsibilities:
- Answer questions using company knowledge base
- Retrieve relevant policies and procedures
- Extract information from contracts and agreements
- Synthesize information across multiple documents
- Provide contextual explanations with source citations
Optimized Retrieval:
- Hybrid Search: Combine vector similarity with keyword matching
- Metadata Filtering: Pre-filter by document type, date, department before similarity search
- Reranking: Use cross-encoder models to rerank retrieved chunks for relevance
- Context Window Management: Optimize chunk sizes for LLM context limits
- Query Expansion: Automatically expand queries with synonyms and related terms
3.3 Hybrid Intelligence Agent
Responsibilities:
- Combine structured financial data with unstructured business context
- Answer questions requiring both transactional analysis and policy knowledge
- Provide enriched insights by joining quantitative and qualitative information
- Support decision-making with comprehensive data views
Orchestration Pattern:
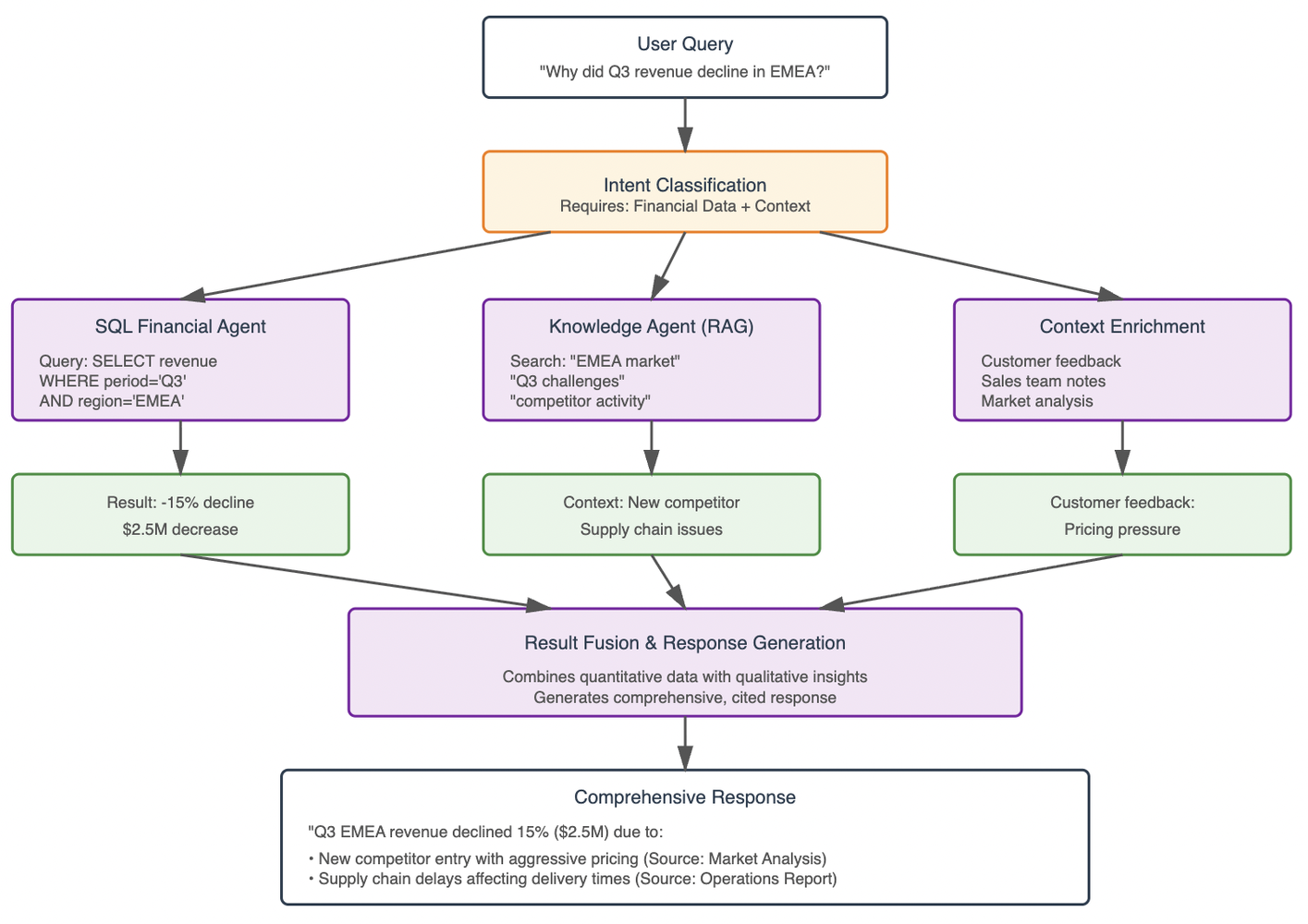
Example Use Case:
- Query: “Why did our Q3 revenue decline in the EMEA region?”
- SQL Agent: Retrieves Q3 revenue by region, identifies 15% decline in EMEA
- Knowledge Agent: Retrieves market analysis reports, sales meeting notes, customer feedback
- Fusion: Combines quantitative decline with qualitative factors (competitor entry, pricing pressure, supply chain issues)
- Response: Comprehensive analysis with numbers, context, and recommendations
4. Infrastructure and Performance Considerations
4.1 Storage Architecture
Transactional Database:
- Configuration: Write-optimized for real-time transaction ingestion
- Read Replicas: Separate replicas for analytics queries to avoid contention
- Partitioning: Time-based partitioning for transaction tables
- Retention Policy: Archive historical data to cold storage after defined period
- Backup Strategy: Continuous backup with point-in-time recovery
Master Data Database:
- Configuration: Balanced read-write performance
- Caching Layer: Redis for frequently accessed master records
- Search Index: Elasticsearch for fast text search on master data attributes
Vector Database:
- Dimensionality: Match embedding model output (e.g., 1536 for OpenAI Ada)
- Index Type: HNSW or similar for fast approximate nearest neighbor search
- Metadata Fields: Extensive metadata for filtering and classification
- Scaling: Horizontal scaling for large knowledge bases
Document Storage:
- Purpose: Store original documents for audit and reference
- Organization: Hierarchical structure by document type, date, entity
- Lifecycle: Automatic tiering to cheaper storage classes over time
- Access Control: Fine-grained permissions aligned with data sensitivity
4.2 Performance Optimization
Query Optimization:
- Prepared Statements: Reuse query plans for common patterns
- Connection Pooling: Maintain persistent database connections
- Batch Processing: Group operations to reduce round trips
- Asynchronous Processing: Non-blocking operations for long-running queries
Caching Strategy:
- Application Cache: Cache master data, frequent queries, embeddings
- Result Cache: Store results of expensive calculations
- CDN: Cache static content and common API responses
- Cache Invalidation: Event-driven invalidation on data updates
Scalability Approach:
- Horizontal Scaling: Add nodes for increased throughput
- Load Balancing: Distribute requests across multiple service instances
- Microservices: Separate ingestion, query, and retrieval services
- Auto-Scaling: Dynamic resource allocation based on demand
5. Security and Compliance
5.1 Data Security Measures
Encryption:
- At Rest: AES-256 encryption for all stored data
- In Transit: TLS 1.3 for all data transmission
- Key Management: Hardware security modules (HSM) for key storage
Access Control:
- Authentication: Multi-factor authentication for all users
- Authorization: Role-based access control (RBAC) with fine-grained permissions
- Row-Level Security: Filter data based on user roles and organizational hierarchy
- API Security: OAuth 2.0, API keys with rate limiting
Audit and Monitoring:
- Access Logging: Record all data access with user, timestamp, query details
- Change Tracking: Audit trail for all data modifications
- Anomaly Detection: Monitor for unusual access patterns or data exfiltration
- Compliance Reporting: Generate audit reports for regulatory requirements
5.2 Privacy and Data Governance
Data Classification:
- Public: Non-sensitive business information
- Internal: General business data for employees
- Confidential: Sensitive business data with restricted access
- Highly Confidential: Financial data, PII, trade secrets
Privacy Controls:
- Data Minimization: Collect and retain only necessary data
- Anonymization: Mask or tokenize PII where full data not required
- Consent Management: Track data usage consent and permissions
- Right to Erasure: Support data deletion requests (GDPR compliance)
Retention Policies:
- Transactional Data: Retain per legal requirements (typically 7-10 years)
- Master Data: Retain active records, archive inactive with defined schedule
- Documents: Retain per document type and regulatory requirements
- Logs: Retain 90 days hot, 1 year warm, 7 years cold storage
6. Implementation Roadmap
Phase 1: Foundation
- Set up core infrastructure (databases, storage, compute)
- Implement transactional data ingestion pipeline
- Develop standardized transaction schema and transformation rules
- Create SQL-based Financial Transaction Agent
- Establish data quality and validation framework
Phase 2: Master Data and Integration
- Implement MDM layer for customer, product, vendor data
- Develop batch ingestion pipelines for external systems
- Create API connectors for major ERP and CRM platforms
- Build hybrid query capabilities combining transactional and master data
- Establish security and access control framework
Phase 3: Knowledge Base and RAG
- Set up vector database infrastructure
- Implement document ingestion and processing pipeline
- Develop embedding generation and storage processes
- Create RAG-based Knowledge Retrieval Agent
- Build metadata management and classification system
Phase 4: Advanced Capabilities
- Implement Hybrid Intelligence Agent
- Develop real-time streaming ingestion
- Create advanced analytics and ML model integration
- Establish comprehensive monitoring and alerting
- Optimize performance and scalability
Phase 5: Production Hardening
- Complete security audit and penetration testing
- Achieve compliance certifications (SOC 2, ISO 27001)
- Implement disaster recovery and business continuity
- Conduct load testing and performance optimization
- Develop comprehensive documentation and training
7. Key Success Factors
Data Quality:
- Establish data stewardship roles and responsibilities
- Implement continuous data quality monitoring
- Create feedback loops for data issue resolution
Performance:
- Monitor query performance and optimize slow queries
- Regularly review and update indexes and partitions
- Conduct capacity planning for growth
User Adoption:
- Provide intuitive interfaces for data exploration
- Offer training on agent capabilities and limitations
- Gather user feedback for continuous improvement
Governance:
- Establish clear data ownership and accountability
- Document data lineage and transformation logic
- Regular compliance audits and certification maintenance
Conclusion
A well-architected data ingestion strategy is critical for financial AI agent platforms. The hybrid approach combining structured relational databases for transactional and master data with vector databases for unstructured knowledge provides the optimal foundation. This architecture enables specialized agents to efficiently access and process diverse data types while maintaining performance, security, and compliance requirements.
The key differentiation lies in:
- Intelligent data classification – storing each data type in its optimal format
- Specialized agent access patterns – SQL agents for structured queries, RAG agents for unstructured retrieval, hybrid agents for comprehensive insights
- Robust data quality framework – ensuring accuracy and reliability
- Scalable architecture – supporting growth in data volume and user base
- Enterprise-grade security – protecting sensitive financial information
Success requires careful planning, phased implementation, and continuous optimization based on real-world usage patterns and evolving business requirements.