The Power of Reflection: Why the Best AI Agents Question Themselves
Last week, an AI agent cost me hours of wasted work.
The financial analysis looked perfect. Immaculate spreadsheet. Beautiful charts.
Completely wrong conclusions.
The agent had misinterpreted a key metric. Everything that followed was flawed. This moment revealed something fundamental: intelligence without reflection is just confident incompetence.
How Humans Actually Think
Consider how you write an important email. You draft it. Read it back. Catch the awkward phrasing. Soften the tone. Maybe ask a colleague to review it.
This loop: create, critique, refine – is so natural we barely notice it. Yet most AI agents skip this entirely. They execute in a single pass and move on, regardless of quality.
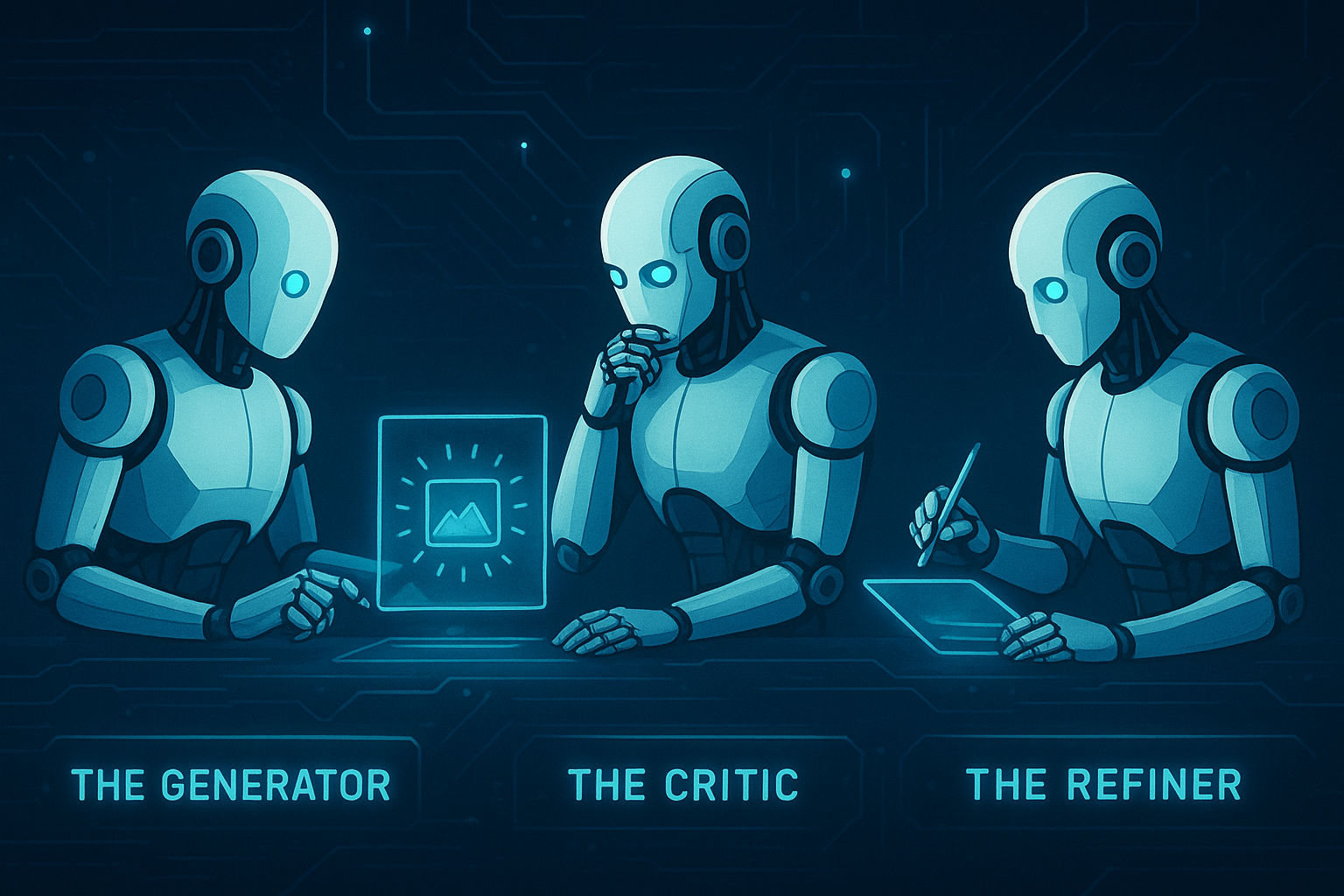
The solution? A three-agent architecture that brings human-style self-correction to AI:
- The Generator creates the initial output
- The Critic examines it for errors, gaps, and improvements
- The Refiner combines both to produce the final result
Why One-Shot Agents Fail
You ask an AI agent to write Python code that flags unusual customer transactions. It produces:
def find_anomalies(transactions):
avg = sum(transactions) / len(transactions)
return [t for t in transactions if t > avg * 2]Clean. Concise. Inadequate.
The code crashes on empty lists. A single large transaction skews the average and hides real anomalies. The 2x threshold is arbitrary. No error handling. No documentation.
A human developer catches these issues in code review. A single-pass AI agent calls it done.
Reflection in Action
Watch how three agents transform that code:
The difference? Code you can actually deploy versus a prototype that breaks in production.
Real Impact Across Industries
At my work, I’ve seen this pattern transform outcomes across domains:
Legal contracts: A critic spotted ambiguous liability language that could have exposed a client to unlimited damages. The refiner tightened the wording. Potential multi-million dollar save.
The Generator produces the initial version.
The Critic dissects it: missing error handling, mean-based detection fails with outliers, arbitrary threshold, no documentation.
The Refiner delivers production-ready code with proper IQR-based detection, input validation, clear documentation, and configurable parameters.
System architecture: When designing transaction processing, a generator proposed microservices. The critic identified race conditions and missing rollback mechanisms. The refiner produced an event-sourced design with proper guarantees—preventing a production catastrophe.
Marketing campaigns: One team using this approach cut revision cycles by 60% while improving audience response. The critic caught brand inconsistencies and cultural sensitivities the generator missed.
Medical support: A diagnostic agent suggests conditions. A critic flags contraindications and drug interactions. A refiner produces a comprehensive assessment. This doesn’t replace physicians, it makes them more thorough.
What Makes Critique Work
Not all criticism helps. Compare these:
Weak: “This analysis is incomplete.”
Strong: “The revenue analysis is solid, but we’re missing cost structure. Without margin trends, we can’t tell if growth is sustainable. Add a gross margin section covering the same period.”
Good critique acknowledges what works, identifies specific gaps, explains impact, and provides clear direction.
Three Keys to Implementation
Give full context: Each agent needs the complete original requirements. I’ve seen systems where critics only saw the output, leading to “improvements” that no longer solved the actual problem.
Specialize your agents: Your generator needs creativity. Your critic needs precision. Your refiner needs synthesis. Use different model configurations for each role.
Limit iterations: Set clear bounds (1-3 cycles) with termination conditions. Otherwise you get infinite loops of critique and refinement.
When to Use (and Skip) Reflection
Use this pattern when quality criteria are clear, improvement can be assessed objectively, and stakes justify the cost.
Skip it for low-stakes, high-volume tasks where speed trumps refinement, or pure creativity matters more than correctness.
Remember: reflection augments human judgment in high-stakes domains, it doesn’t replace it.
The Bigger Shift Happening
As AI agents gain autonomy, reflection becomes essential, not optional.
An agent managing infrastructure must question its decisions. An agent providing medical information must challenge its reasoning. An agent handling financial transactions must verify its logic.
We’re building AI systems that don’t just execute tasks but think about their thinking. They pause. They question. They refine.
The future belongs not to agents that answer fastest, but to those that answer best – having challenged their own assumptions along the way.
The reflection pattern isn’t just technical architecture. It’s a fundamental principle: intelligent systems should embody humility and rigor, recognizing that first attempts are rarely final answers.
Intelligence isn’t measured by how quickly you solve a problem. It’s measured by whether you have the wisdom to question your own solution.